[JPA] 영속성 컨텍스트
JPA를 사용하기 위해서는 영속성 컨텍스트라는 것을 정확하게 이해 할 필요가 있다.
객체지향과 RDB와의 패러다임을 없애주는 요소이기도 하며 JPA의 내부가 어떻게 동작하는지 이해할 수 있는 방향이기도 하다.
먼저, 우리가 JPA에서 데이터를 저장할 때 사용하는 persist()는 정확하게는 데이터를 저장시키는 메소드가 아니다.
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("testUnit");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Board board = new Board();
board.setTitle("testTitle");
em.persist(board);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}이런 코드가 있을 때 persist가 데이터를 저장하는 메소드라면 persist를 사용했을 때 JPA가 DB에 쿼리를 보내야 할텐데 코드를 실행하여 로그를 살펴보면 바로 쿼리를 보내지 않는다.
그렇다면 언제 쿼리가 전송되서 데이터가 DB에 저장되는걸까?
바로 트랜잭션이 끝나는 시점이다.
JPA가 쿼리를 DB에 전송하는 시점은 크게 3가지로 나눌 수 있다.
- 강제로 flush()를 동작시키는 시점
- 트랜잭션이 끝나는 시점
- 트랜잭션이 끝날 때 JPA가 flush()를 실행시킨다.
- JPQL을 실행시킨 시점
- JPQL을 이용해서 select를 했다고 가정할 때 앞에서 데이터를 입력하는 쿼리가 있다면 select를 했을 때 앞의 쿼리가 DB로 전송되지 않은 시점이기 때문에 잘못된 데이터를 가져올 수 있다. 그렇기 때문에 모아놓은 쿼리를 먼저 DB로 전송한 후 select를 실행하게 된다.
그렇기때문에 persist를 사용하다고 바로 쿼리가 전송되는 것이 아니다.
그렇다면 persist는 어떤일을 하는 메소드일까??
여기서 바로 영속성 컨텍스트가 등장한다.
JPA는 내부적으로 캐시를 하나 가지고 있다. persist를 하게되거나 DB에서 데이터를 조회하게 되면 JPA는 이 캐시에 해당 데이터를 가지고있게 된다.

데이터를 조회하는 경우 가장 먼저 1차캐시에 찾는 데이터가 있는지 확인하고 없을 경우 DB에서 데이터를 조회한 후 1차캐시에 저장하고 값을 반환한다.
만약 조회했을 때 1차 캐시에 데이터가 있다면 DB까지 가지않고 1차 캐시에 있는 데이터를 바로 반환한다.
우리가 persist를 동작시켰을 때 또는 DB에서 데이터를 조회했을 때 해당하는 데이터를 그림의 캐시부분에 저장해놓는다.
이렇게 캐시에 저장된 데이터는 트랜잭션안에서만 존재할 수 있다. 트랜잭션이 끝나는 순간 캐시에 저장된 데이터도 사라지게된다.
이렇게 데이터가 캐시에 저장되서 관리되는 상태를 영속상태라고 한다.
만약 영속상태인 데이터가 트랜잭션내에서 값이 변경된다면 JPA가 캐시에 있는 데이터와 비교해서 update문을 만들어놓는다. 이러한 이유로 JPA를 사용하면 update코드를 따로 만들필요가 없고 그냥 자바에서 객체를 사용하듯이 사용하기만 해도 JPA가 자동으로 update문을 만들어서 데이터를 바꿔준다.
코드로 한번 살펴보자
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("testUnit");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Board board = em.find(Board.class, 1L); // Board에서 ID가 1인 값을 조회한다.
System.out.println("========== Title = " + board.getTitle() + " ===========");
board.setTitle("updateTitle"); // title값을 변경
em.flush(); // 강제로 DB에 쿼리전송
Board findBoard = em.find(Board.class, 1L); // 위와 같은 아이디값으로 다시 조회
System.out.println("========== findBoard = " + findBoard.getTitle() + " ===========");
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}
먼저 기존에 Board테이블에 입력해놓은 데이터를 조회해온다. 그리고 가져온 데이터의 title값을 변경한 후 flush()를 이용해 강제로 쿼리를 DB에 전송한 뒤 다시 데이터를 조회해하면 데이터가 바뀐것을 볼 수 있다.
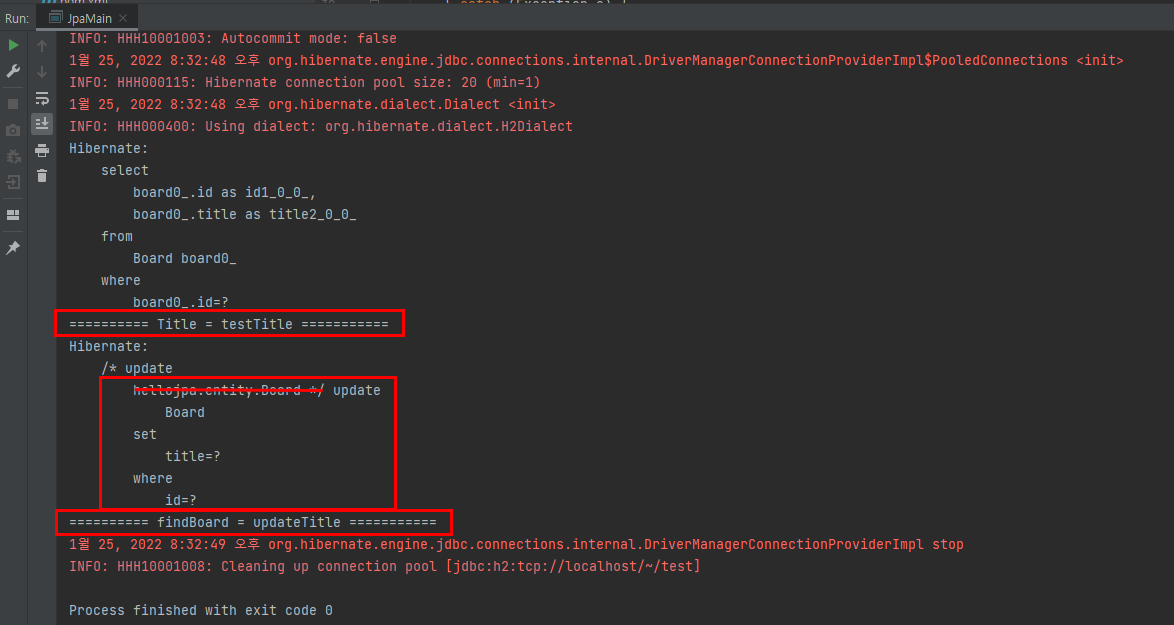
코드를 실행한 로그를 보면 분명 코드에서는 데이터를 가져온 뒤 값을 변경하고 다시 쿼리를 날리기만 했을 뿐인데 JPA가 자동으로 update문을 실행시킨 것을 볼 수 있다. 그리고 확인을 위해 출력한 title값도 바뀐것을 볼 수 있다.
만약 우리가 JPA가 아니라 MyBatis등의 다른 라이브러리를 사용했다면 변경되는 부분을 감지하는 코드와 update문을 우리가 직접 만들어야 할 것이다. 하지만 JPA는 이러한 부분을 직접 해줌으로서 코드를 작성하면서 나타날 실수적인 부분도 없애주고 객체지향과 RDB의 패러다임 불일치도 해결해주고 있다.
영속상태인 데이터는 JPA가 관리를 해주지만 만약 이 캐시에서 벗어나 있는 데이터라면 JPA가 관리해주지 못한다.
영속상태인 데이터가 어떤 이유로 영속상태가 아닌 상태가 된것을 준영속상태라고 표현한다. 처음부터 영속상태에 들어오지 못한 데이터는 비영속상태라고 한다.
영속상태인 데이터를 준영속상태로 만드는 방법은 3가지가 있다.
- detach(entity) : 지정한 entity를 준영속상태로 만든다.
- clear() : 영속상태인 모든 데이터를 준영속상태로 만든다.
- close() : EntityManager자체를 종료시킨다.
이러한 방법으로 준영속상태가 된 데이터들은 JPA의 관리대상이 아니기 때문에 데이터가 변경되더라도 update문이 나가지 않게된다. 이점을 꼭 주의해서 사용하기 바란다..!
'JPA' 카테고리의 다른 글
| QueryDSL 사용이유와 사용방법 (0) | 2022.06.22 |
|---|---|
| 연관관계 매핑(단방향) (0) | 2022.04.09 |
| [JPA] EntityManager (0) | 2022.02.01 |
| [JPA] 프로젝트 생성 (0) | 2022.01.31 |
| [JPA] JPA 알아보기 (0) | 2022.01.31 |